 Dashboard
Dashboard
 Federator
Federator
 Patient Browser
Patient Browser
 HAPI FHIR Server
HAPI FHIR Server
 Patient Transfer Dashboard
Patient Browser
HAPI FHIR Server
Patient Transfer Dashboard
Patient Transfer Dashboard
Patient Browser
HAPI FHIR Server
Patient Transfer Dashboard
Foundation for Federated Data Architecture
Overview
The Foundation for Federated Data Architecture defines a secure, scalable, and policy-driven approach to sharing data across independent organizations, systems, or jurisdictions. It enables real-time synchronization, role-based access, and privacy-first data exchange without requiring central control or ownership. The model is built on four key domains: Data Emitters, Security and Governance, Federated Infrastructure, and General Users.
Architecture Diagram

Data Emitters and Users
- Data Emitter Nodes: Original sources of data operated by individual partners. These nodes retain full ownership and apply local governance policies before releasing data to others.
- General Users: Authorized systems or users that access governed, aggregated outputs through standard interfaces. Data access is approved, compliant, and auditable by design.
Security, Control, Governance and Enforcement
- Access Control Models: Define who can access which data, under what conditions, and for what purpose. These models are flexible and respect each partner’s legal and privacy frameworks.
- Data Governance Gateway: Governs all data requests through a centralized decision engine. It checks for appropriate permissions, agreements, and compliance requirements before granting access.
- Policy Enforcement: Applies runtime rules such as expiry windows, purpose-of-use restrictions, and consent checks. Ensures governance is enforced continuously and automatically.
- Security Protocols: Enforces encryption, identity validation, and secure communication across all participants. Aligns with national privacy legislation and modern security practices.
Infrastructure, Storage, Query and Standards
- Cloud Platforms: Provide the infrastructure for deploying and operating federation components. Each partner manages its own environment while maintaining interoperability.
- API Management: Facilitates secure data exchange through consistent APIs. Includes validation, rate limiting, authentication, and full traceability of all interactions.
- Data Storage Solutions: Host datasets securely with encryption, audit trails, and access controls. Support both local data and aggregated, cross-jurisdictional information.
- Data Standards: Use formats such as HL7 FHIR to ensure consistency and machine readability. Standards support seamless integration and shared understanding across systems.
- Real Time Data Sync: Keeps systems aligned using event-driven updates and automated pipelines. Maintains data freshness without compromising autonomy or performance.
Summary
This architecture is not only a technical model but also a governance framework that respects local control, enforces compliance, and builds trust. It enables real-time collaboration across distributed data environments by combining secure infrastructure, enforceable policy, and interoperable standards. Whether applied in health, climate, finance, or public safety, it offers a flexible and future-ready foundation for secure data collaboration at scale.
Technical Architecture
Overview
The IIDI technical architecture operationalizes the foundational domains of the Federated Data Architecture model: Data Emitters & General Users, Security, Control, Governance & Enforcement, and Infrastructure, Storage, Query & Standards. Each deployed component in the Kubernetes platform directly corresponds to one or more of these foundational domains.
Data Emitters & General Users
- FHIR Immunization Registries: Provincial HAPI FHIR Servers act as data emitter nodes, serving as authoritative sources of immunization records.
- Synthesizer: Generates FHIR-compliant synthetic patient data to support system testing, demo flows, and validation.
- SMART Patient Viewer: Enables healthcare providers (general users) to securely access immunization records through a standardized interface.
Security, Control, Governance & Enforcement
- Istio with mTLS: Enforces secure, mutually authenticated communication between services. Ensures policy enforcement at runtime.
- Transfer Services: Outbound and Inbound Transfer components apply FHIR validation, policy enforcement, and jurisdictional access control prior to any data exchange.
- Redis: Provides asynchronous job queuing with backpressure and retry handling, ensuring fault-tolerant and governed data delivery.
- Aggregator: Performs de-identification and summarization at the PT level, enforcing local governance rules before reporting to PHAC.
Infrastructure, Storage, Query & Standards
- Kubernetes Namespaces (BC, ON, PHAC): Isolate workloads across jurisdictions and the federal level, ensuring multi-tenant security and operational autonomy.
- Containerized Microservices: All components (FHIR servers, aggregators, dashboards, etc.) are deployed as containers for resilience and scalability.
- Event-Driven Architecture: Supports real-time data sync and decoupling through Redis and asynchronous service communication.
- HL7 FHIR: Data is exchanged using the HL7 FHIR standard, ensuring semantic interoperability and consistent representation across systems.
- R Shiny Dashboard (PHAC): Hosts aggregated, de-identified data from PTs, enabling national immunization reporting and insight generation.
Architecture Diagram
Each technical component is shown in the cluster diagram below, with color-coded mappings to its corresponding foundational pillar.

Summary
The IIDI technical architecture translates high-level federation principles into a working, production-grade implementation. Each component — from secure data emitters to governed aggregation and federated APIs — has been deliberately mapped to the foundational pillars of the federated model. Through Kubernetes, containerized services, Istio, Redis, and HL7 FHIR, the platform enables real-time, standards-compliant immunization data sharing across jurisdictions, all while maintaining local autonomy and national coordination. The architecture prioritizes security, resilience, and future scalability — laying the groundwork for broader public health applications beyond immunization.
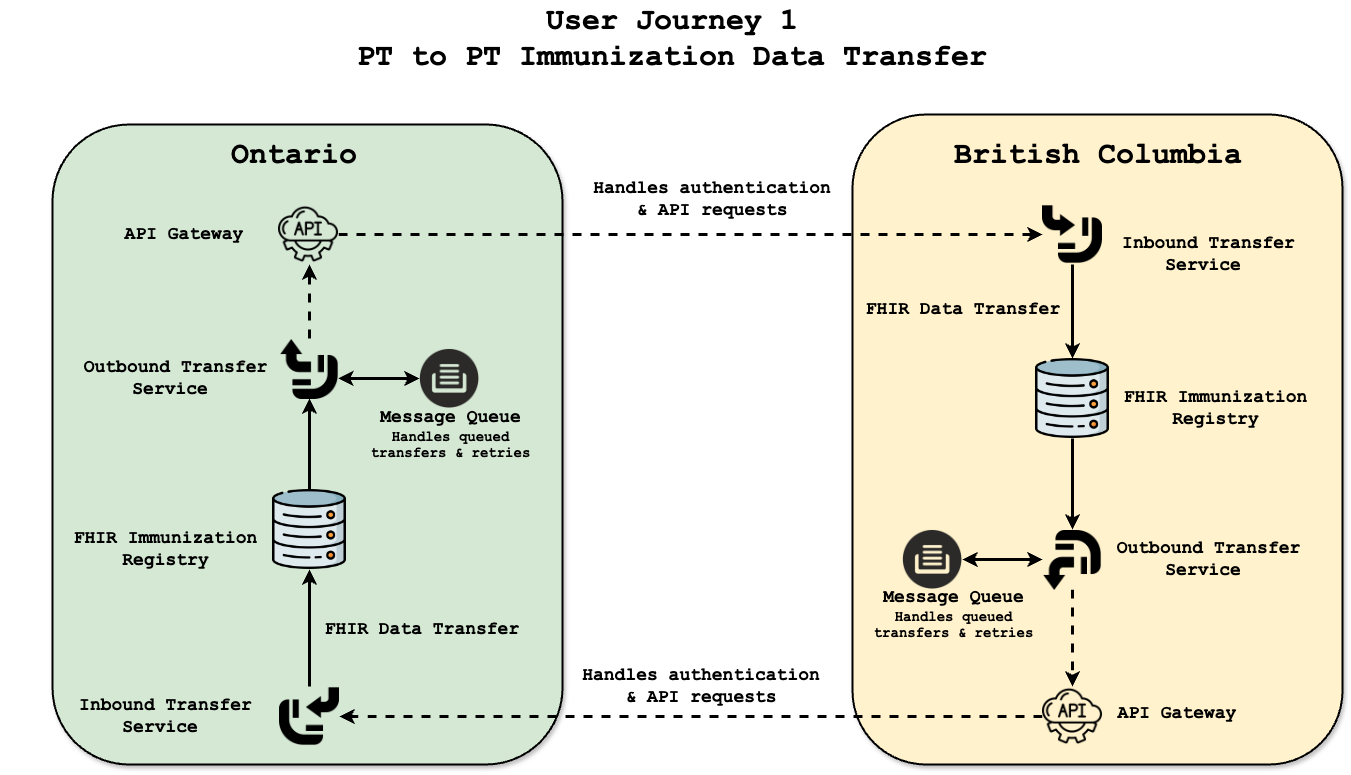
User Journey 1: PT-to-PT Transfer
Overview: Secure Movement of Immunization Records Across Jurisdictions
The PT-to-PT transfer capability represents a foundational pillar of the Interoperable Immunization Data Initiative (IIDI). It enables the secure, structured, and standards-aligned movement of patient immunization records when individuals relocate between provinces or territories. This journey reflects real-world clinical workflows, empowering jurisdictions to preserve patient continuity of care while maintaining data sovereignty and regulatory compliance.
Unlike centralized models, this federated approach avoids direct data aggregation. Instead, immunization records are transmitted securely from one jurisdiction to another using modern interoperability protocols and runtime policy enforcement. The model reinforces trust between jurisdictions by validating consent, applying consistent data standards, and ensuring all transfers are fully auditable.
Key Federated Components Enabling PT-to-PT Transfer
- API Gateway: Facilitates secure, authorized communication between the outbound and inbound services.
- FHIR Data Exchange: Immunization records are structured using HL7 FHIR standards, ensuring semantic interoperability.
- Redis Message Queue: Provides asynchronous job queuing with fault tolerance, enabling retry mechanisms and rate limiting.
- Transfer-Outbound Service: Authenticates, packages, and sends records from the origin jurisdiction after consent validation.
- Transfer-Inbound Service: Verifies integrity, enforces policy, and ingests records into the receiving jurisdiction’s FHIR registry.
Technical Flow of a Cross-Jurisdiction Transfer
- The patient relocates to a new province or seeks care in a different jurisdiction.
- The originating province completes consent checks and authorizes the outbound request.
- The Transfer-Outbound service securely packages the FHIR-formatted payload and pushes it to Redis.
- The Transfer-Inbound service at the receiving jurisdiction polls Redis, validates the request, and ensures compliance with HL7 FHIR.
- Upon successful validation, the record is written into the receiving jurisdiction’s HAPI FHIR server and becomes queryable.
What Data Is Transferred?
The PT-to-PT transfer includes only essential, structured information required for safe clinical continuity. All payloads are formatted using HL7 FHIR and exclude unnecessary or non-consented details.
| Category | Data Elements |
|---|---|
| Patient Information |
|
| Immunization History |
|
| Metadata |
|
Safeguards, Scope, and Key Clarifications
- All data is synthetic and anonymized, designed solely for demonstration and validation purposes.
- Consent validation must occur externally and is assumed as a precondition for any data exchange.
- This is a push-based model — receiving jurisdictions do not pull or request patient data independently.
- Manual transfers (fax/email) are considered out of scope for this model.
- The current proof of concept focuses on MMR vaccines but can support additional vaccine types in future iterations.
- Optional user interface demos can visualize transferred records in real-time via SMART Viewer or API query.
Summary
PT-to-PT transfer is a critical step toward modernizing Canada’s immunization data ecosystem. It enables provinces to securely exchange structured health records while maintaining autonomy and enforcing local governance. By combining FHIR standards, secure message queues, consent-aware services, and runtime policy enforcement, IIDI delivers a highly portable and scalable foundation for cross-jurisdictional data sharing.
This user journey shows that interoperable health data is possible without centralization. Instead, it highlights how a federated model — backed by technical rigour, real-world workflows, and strong trust boundaries — can support secure, patient-centred data exchange across Canada’s diverse health systems.
User Journey 2: Federated Immunization Data Architecture
Overview: Federated, Privacy-Preserving Public Health Surveillance
This user journey demonstrates how immunization data from provincial and territorial registries can be securely aggregated and reported to PHAC — without ever relinquishing patient-level control. Instead of centralizing health data, the architecture follows a federated model, in which each jurisdiction governs its own data pipelines and contributes only structured, de-identified insights for national surveillance. This design supports public trust, legal compliance, and analytical consistency across Canada’s diverse health landscape.
Provincial Components
- FHIR Immunization Registries: Source of truth for immunization records (e.g., BC, ON).
- Synthetic Data Generator: Simulates realistic, FHIR-compliant records for safe validation and testing.
- SMART Patient Viewer: Supports local user access to jurisdiction-governed records.
- Aggregator: Performs summarization and de-identification at the provincial level before reporting to PHAC.
Federal Components
- Federator (PHAC): Receives structured, anonymized data sets and enforces validation policies.
- R Shiny Dashboards: Delivers visual insights to support national decision-making, coverage analysis, and vaccine equity.
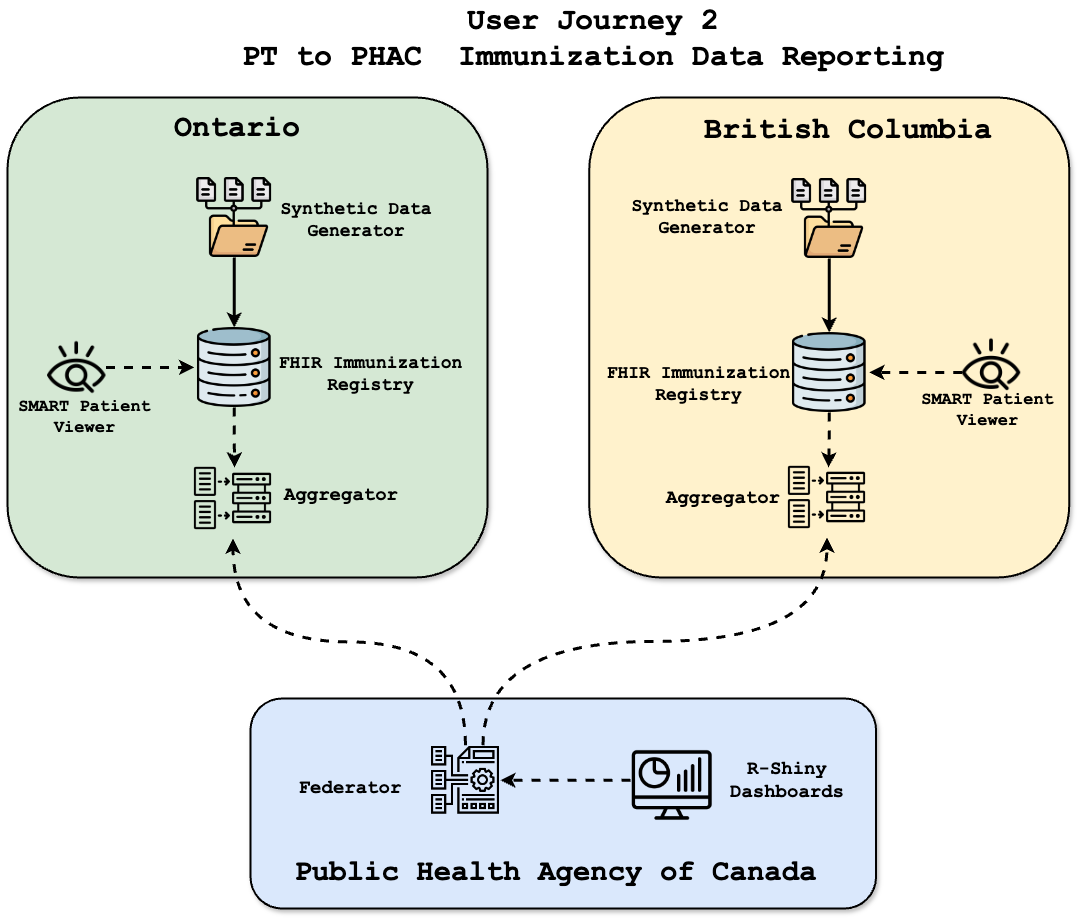
Data Flow and Governance
- An authorized request triggers the aggregation process at the provincial level.
- Access control systems validate authentication, authorization, and jurisdictional policies.
- The Aggregator extracts immunization records from the FHIR registry, applies de-identification, and formats data to a shared schema.
- The anonymized payload is securely transmitted to PHAC’s Federator using mTLS encryption and audit logging.
- PHAC validates and ingests the report for national analytics — without ever accessing identifiable PHI.
Core Design Principles
- Provincial Autonomy: Data never leaves a jurisdiction in raw form — PTs control aggregation and transmission.
- Privacy by Design: All de-identification occurs locally, before any report reaches PHAC.
- Analytical Integrity: Aggregation adheres to HL7 FHIR-based schemas, ensuring national consistency despite system diversity.
- PHAC Receives Only What Is Needed: Summarized, structured reports — not patient-level records — power national surveillance.
How Aggregation Works at the PT Level
- FHIR immunization records are queried securely within each provincial registry.
- All identifiers (e.g., names, health numbers, addresses) are stripped before aggregation.
- Records are grouped by jurisdiction, age group, gender, and vaccine type.
- Dose counts and patient totals are calculated per category.
- The final report is formatted into a PHAC-compliant schema and transmitted securely.
Key Data Fields in Aggregated Reports
| Field | Description |
|---|---|
| Reference Date | When the immunization occurred (aggregated format) |
| Jurisdiction | Province or territory (e.g., BC, ON) |
| Age Group | Binned age ranges (e.g., 0–2, 3–5, etc.) |
| Gender | Aggregated by reported gender category |
| Vaccine Type | CVX or vaccine category (e.g., MMR) |
| Dose Count | Total doses administered in the reporting window |
| Total Patients Vaccinated | Unique individuals included in the report |
Public Health Impact and National Value
- Minimizes risk by avoiding transmission of personal identifiers
- Strengthens trust between provinces and PHAC through clear governance and auditability
- Reduces manual reporting overhead by providing real-time, structured updates
- Supports agile decision-making and cross-jurisdictional comparison via dashboards
Clarifications and Assumptions
- De-Identification Responsibility: PHAC never de-identifies data. This is strictly handled by PTs before aggregation.
- Aggregation Scope: PHAC does not fetch or query patient data. Only pre-aggregated summaries are accepted.
Summary
The Federated Immunization Data Architecture redefines how public health intelligence can be gathered across Canada — securely, respectfully, and efficiently. It proves that meaningful data aggregation does not require centralization or compromise on privacy. Instead, it demonstrates a scalable trust model: one that allows PHAC to access timely insights without ever touching raw personal data.
Through strong provincial ownership, secure interfaces, and structured standards like HL7 FHIR, this model balances local autonomy with national accountability. It offers a replicable, privacy-preserving pattern for other public health domains — from COVID surveillance to vaccine equity to broader disease analytics.
Synthetic Patient Data Generation
Overview: Safe, Realistic, Standards-Compliant Data for Interoperability Testing
To enable safe experimentation and validation of cross-jurisdictional workflows, the IIDI platform generates synthetic immunization data that mirrors real-world records without exposing personal health information (PHI). These records are formatted using the HL7 FHIR standard and reflect variations in provincial data models — ensuring both realism and jurisdictional fidelity.
Synthetic data is used to test FHIR endpoints, simulate patient movement between provinces, validate dashboard pipelines, and support continuous development without compromising privacy. Each generated patient, immunization, and allergy record is deterministic, governed, and fully traceable.
FHIR Patient Resource Structure
Each synthetic patient record follows the FHIR Patient resource schema, including core identifiers and demographic extensions:
| Field | FHIR Path | Example Value | Logic |
|---|---|---|---|
| Patient ID | Patient.id | "patient-001" | Unique, auto-generated UUID |
| Name | Patient.name | {"family": "Singh", "given": ["Simar"]} | Faker-generated name with diverse samples |
| Gender | Patient.gender | "male", "female", "other" | Random selection |
| Birth Date | Patient.birthDate | "2012-06-15" | Randomized within pediatric age cohorts |
| Address | Patient.address | {"city": "Toronto", "state": "ON"} | Province-specific logic to simulate local residency |
Provincial Variations in Data Generation
The generator accounts for jurisdictional rules by customizing fields per province:
British Columbia (BC)
- Includes AllergyIntolerance resources
- Uses SNOMED-CT codes for allergy types
- Captures severity and onset date
Ontario (ON)
- No allergy data is generated for ON patients
- FHIR bundles exclude the AllergyIntolerance resource
FHIR Immunization Resource Structure
Each synthetic patient is linked to multiple immunization records with the following structure:
| Field | FHIR Path | Example Value | Logic |
|---|---|---|---|
| Vaccine Type | Immunization.vaccineCode | "MMR", "Influenza" | Random draw from supported vaccine types |
| Manufacturer | Immunization.manufacturer | "Pfizer", "Moderna" | Randomly assigned from list of vendors |
| Dose Number | Immunization.protocolApplied.doseNumber | 1, 2 | Sequential or randomized per patient profile |
Summary
The synthetic data engine plays a foundational role in enabling rapid development, demonstration, and validation of IIDI architecture components. It replicates real-world variability while preserving full privacy, allowing provinces and the federal government to simulate end-to-end data flows without relying on production data.
Its strict alignment with FHIR standards and support for jurisdiction-specific nuances (e.g., BC vs. ON) ensures that interoperability testing remains grounded in actual data behavior — preparing the system for real-world onboarding in the future.
GitHub Repository & Infrastructure
Overview
The Interoperable Immunization Data Initiative (IIDI) is built using a secure, scalable, and federated model. The architecture enables seamless data exchange while ensuring that provincial and territorial jurisdictions maintain control over their immunization records.
GitHub Repository
The source code and related documentation for IIDI can be found in the official GitHub repository:
Infrastructure
The IIDI technical stack is designed for interoperability, security, and compliance with public health data governance frameworks. Key infrastrcutural components are documented below:
- GCP Infrastructure Overview - High-level infrastructure design for deployment.

Architecture Review Board Documentation
The architecture follows a federated data model to support two primary user journeys: